In most of these cases, victims had MFA enabled in their infrastructure, but nonetheless, Audit Logs did not immediately shed light to any anomalous activities. Empirically, when running against a wall of unexplained initial compromise, the main culprit would be Phishing campaigns. However, traditional detection methods for Phishing were not yielding any results in this new wave of incidents. For example, during an old-school phishing attempt, and when MFA is enabled, very often attackers would utilize MFA fatigue to bypass the second layer of authentication, which leaves sufficient IoCs behind. Nothing similar was to be found in logs any longer!
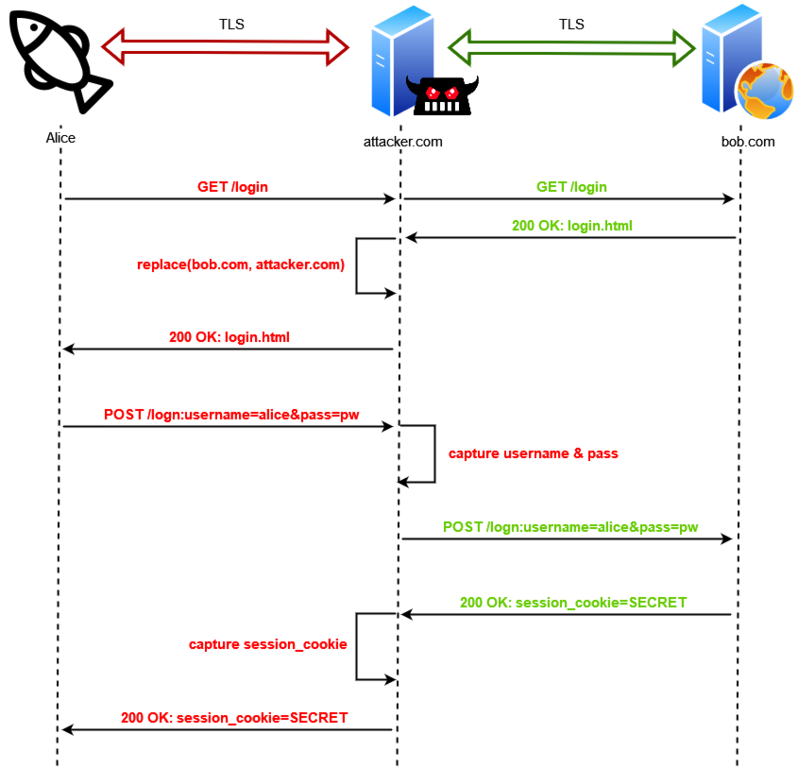
After doing some internal research, our team came to the same conclusion as Microsoft would announce about a month later: Reverse-Proxy phishing frameworks such as EvilginX, Modlishka and Muraena were to blame!
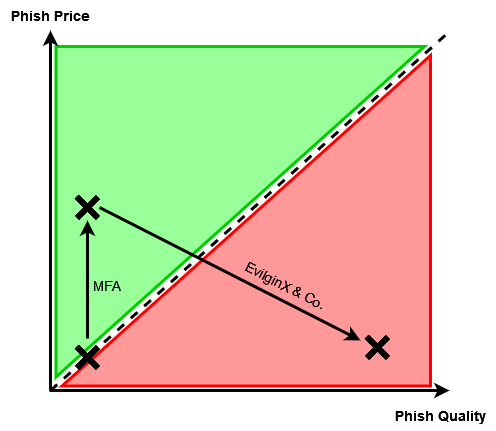
Roughly another year later, by the end of May 2023, Ksandros Apostoli from the SEC Defence team, traveled to Poland to participate in x33fcon, where he attended a talk delivered by none other than the mastermind behind EvilginX, Kuba Gretzky aka @mrgretzky. X33fcon is a purple-team-themed infosec conference, and @mrgretzky was holding an interesting talk about EvilginX there, titled "How much is the Phish?". Additionally in this video made by him you can see how Evilginx catches a phish and completely bypasses MFA on Google.
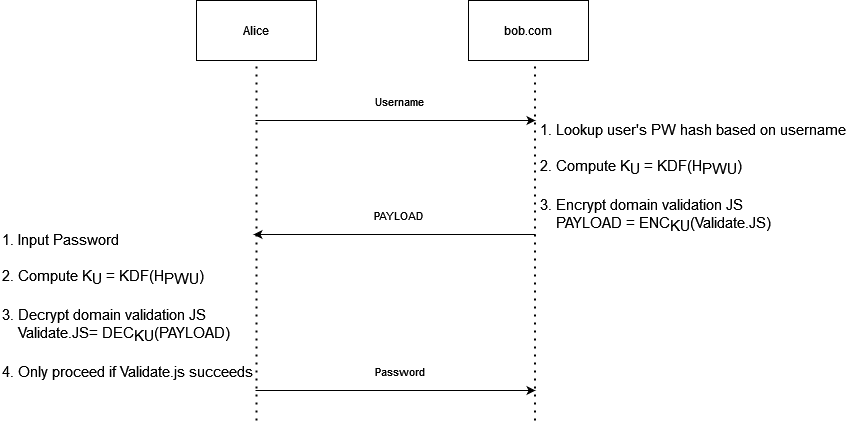
Being part of a purple-team conference, the second half of the talk addressed potential defense mechanisms for reverse-proxy phishing tools such as EvilginX, with a focus on measures that can be implemented by web developers rather than end users. Listening to the proposed techniques in @mrgretzky's presentation, Ksandros came up with an idea that he shared with him after his talk. From the brief interaction they had, Kuba appeared to agree with the presented concept, even at a very high level of abstraction. Ksandros decided to put this idea down on paper and make this article about it for anyone who might want to entertain themselves with the challenging notion of phishing prevention, and the even more challenging ways of implementing it.