Since this blog post got too long and I didn’t want to remove important theory, I marked background knowledge in italic. Feel free to skip these sections if you are already familiar with this knowledge. If you are only interested in the exploitable mimikatz flaws you can jump to chapter “Practice: Analysis of the identified crashes“.
I (René Freingruber from SEC Consult Vulnerability Lab) am going to give a talk at heise devSec (and IT-SECX and DefCamp) about fuzzing binaries for developers and therefore I wanted to test different approaches to fuzz windows applications where source code is available (the audience are most likely developers). To my knowledge there are several blog posts talking about fuzzing Linux applications with AFL or libfuzzer (just compile the application with afl-gcc instead of gcc or add some flags to clang), but there is no blog post explaining the concept and setup for Windows. This blog post tries to fill this gap. Fuzzing is a very important concept during development and therefore all developers should know how to do it correctly and that such a setup can be simple and fast!
Why I Chose Mimikatz As Fuzzing Target
To demonstrate fuzzing I had to find a good target where source code is available. At the same time, I wanted to learn more about the internals of the application by reading the source code. Therefore, my decision fell on mimikatz because it’s an extremely useful tool for security consultants (and hackers) and I always wanted to understand how mimikatz internally works. Mimikatz is a powerful hacker tool for Windows which can be used to extract plaintext credentials, hashes of currently logged on users, machine certificates and many other things. Moreover, mimikatz contains over 261 000 lines of code, must parse many different data structures and is therefore likely to be affected by vulnerabilities itself. At this point I also want to say that penetration testing would not be the same without the amazing work of Benjamin Delpy gentilkiwi, the author of mimikatz.
The next thing I need is a good attack vector. Why should I search for vulnerabilities if there is no real attack vector which can trigger the vulnerability? Mimikatz can be used to dump cleartext credentials and hashes of currently logged in users from the LSASS process. But if there exists a bug in the parsing code of mimikatz, what exactly could I achieve with this? I could just exploit myself because mimikatz gets executed on the same system.
Well, not always. As it turns out, well-educated security consultants and hackers do not directly invoke mimikatz on the owned system. Instead, it’s nowadays widespread practice to create a minidump of the LSASS process on the owned system, download it and invoke mimikatz locally (on the attacker system). Why do we do this? Because dropping mimikatz on the owned system could trigger all kind of alerts (AntiVirus, Application Whitelisting, Windows Logs, …) and because we want to stay under the radar, we don’t want these alerts. Instead, we can use Microsoft signed binaries to dump the LSASS process (e.g.: Task manager, procdump.exe, msbuild.exe or sqldumper.exe).
Now we have a good attack vector! We can create a honeypot, inject some malicious stuff into our own LSASS process, wait until a hacker owns it, dumps the LSASS process and invokes mimikatz on his own system reading our manipulated memory dump file and watch reverse shells coming in! This and similar attack vectors can be interesting features in the future for deception technologies such as CyberTrap (https://www.cybertrap.com/).
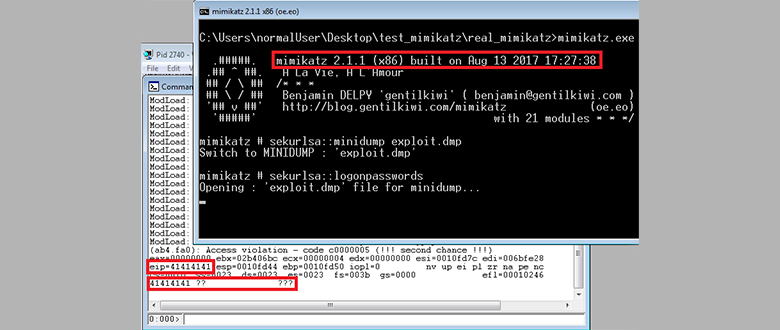
To be fair, exploiting this scenario can be quite difficult because mimikatz is compiled with protections, such as ASLR and DEP, and exploitation of such a client-side application is extremely challenging (we don’t have the luxury of a remote memory leak nor of scripting possibilities such as with browsers or PDF readers). However, such client-side scriptless exploits are not impossible, for example see https://scarybeastsecurity.blogspot.co.at/2016/11/0day-exploit-advancing-exploitation.html. To my surprise, mimikatz contained a very powerful vulnerability which allows us to bypass ASLR (and DEP).
Theory: Fuzzing Windows Binaries
We don’t want to write a mimikatz-specific fuzzer (with knowledge about the parsing structures, implemented checks and so on), instead, we want to use something which is called “coverage-guided fuzzing” (or feedback-based fuzzing). This means we want to extract code coverage information during fuzzing. If one of our mutated input files (the memory dump files) generate more code coverage in mimikatz, we want to add it to our fuzzing queue and fuzz this input later as well. That means we start with one dump file and the fuzzer identifies different code paths itself (ideally all) for us and therefore “learn” all the internal parsing logic autonomously! This also means that we only have to write a fuzzer one time and can use it against nearly all kinds of applications! Luckily for us, we don’t even have to write such a fuzzer because someone else already did an excellent job!
Currently the most commonly used fuzzer is called AFL (American fuzzy lop) and implements exactly this idea. It turned out that AFL is extremely effective in identifying vulnerabilities. In my opinion, this is because of four major characteristics of AFL:
- It is extremely fast.
- It extracts edge coverage (with hit count) and not only code coverage which simplified means that we try to maximize executed “paths” and not “code” (E.g. if we have an IF statement, code coverage would put the input file which executes the code inside the IF into the queue. Edge coverage on the other side would put one entry with, and one entry without the IF body-code into the queue.).
- Because of 1) it can implement deterministic mutation (do every operation on every byte/bit of the input). More on this later when talking about heatmap fuzzing.
- It’s extremely simple to use. Fuzzing can be started within several minutes!
The big question is now: How does AFL extract the code/edge coverage information?
The answer depends on the configured mode of AFL. The default option is to “hack” generated object files from gcc and insert at all possible code locations instrumentation code. There is also a LLVM mode where a LLVM compiler pass is used to insert the instrumentation. And then there is a qemu mode if source code is not available which emulates the binary and adds instrumentation via qemu.
There are several forks which extend AFL with other instrumentation possibilities. For example, hardware features can also be used to extract code coverage (WinAFL-IntelPT, kAFL). Another idea is to use dynamic instrumentation frameworks such as PIN or DynamoRio (e.g. WinAFL). These frameworks can dynamically instrument (during runtime) the target binary which means that a dispatcher loads the next instructions which should be executed and adds additional instrumentation code before (and after) them. All that requires dynamic relocation of the instructions while being completely transparent to the target application. This is quite complicated but the framework hides all that logic from the user. Obviously, this approach is not fast (but works on Windows and has many cool features for the future!).
When source code is available, I thought that there should be the same possibility as AFL does on Linux (with GCC). My first attempt was to use “libfuzzer” on Windows. Libfuzzer is a fuzzer like AFL but it acts on function level fuzzing and is therefore more suitable for developers. AFL fuzzes full binaries per default but can also be started in a persistent mode where it fuzzes on function level. Libfuzzer uses the feature “Source-based code coverage” from the LLVM clang compiler which is exactly what I wanted to use for coverage-information on Windows.
After some initial errors I could compile mimikatz with LLVM on Windows. When adding the flags for “source-based code coverage” I got again some errors which can be fixed by adding the required libraries to the linker include paths. However, this flag added the same functions to all object files which resulted in linker errors. The only way I could solve this was to merge all .c files into one huge file. Since this approach was more a pain than anything else, I didn’t pursue it further for the talk. Note that using LLVM for application analysis on Windows could be a very interesting approach in the future!
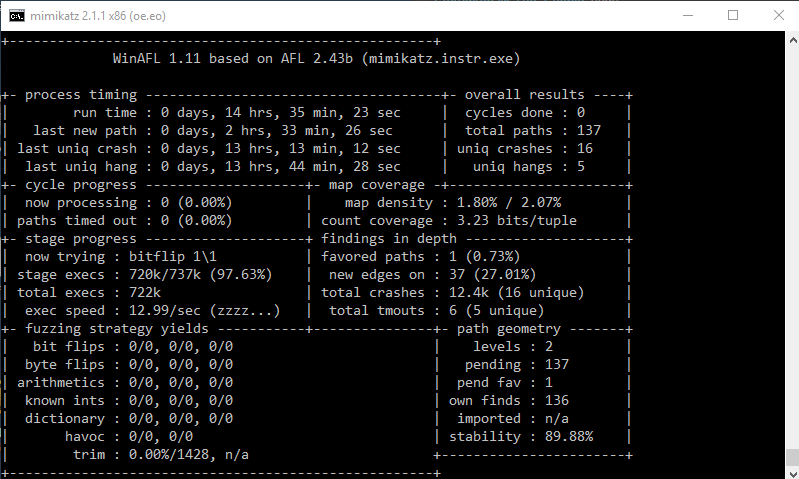
The next thing I tested was WinAFL in syzygy mode and this was exactly what I was looking for! For a more detailed description of syzygy see https://doar-e.github.io/blog/2017/08/05/binary-rewriting-with-syzygy/. At this point I want to thank Ivan Fratric (developer of WinAFL) and Axel 0vercl0k Souchet (developer of the syzygy mode) for their amazing job and of course Michal Zalewski for AFL!
Practice: Fuzzing Windows Binaries
You can download WinAFL from here: https://github.com/ivanfratric/winafl
All we must do is include the header and add the code:
While(__afl_persistent_loop()) {
// code to fuzz
}
to the project which we want to fuzz and compile a 32-bit application with the /PROFILE linker flag (Visual Studio -> project properties -> Linker -> Advanced -> Profile).
For mimikatz I removed the command prompt code from the wmain function (inside mimikatz.c) and just called kuhl_m_sekurlsa_all(argc,argc) because I wanted to directly dump the hashes/passwords from the minidump (issue the sekurlsa::logonpasswords command at program invocation). Since mimikatz would extract this information per default from the LSASS process I added a line inside kuhl_m_sekurlsa_all() to load the dump instead. Moreover, I added the persistent loop inside this function.
Here is how my new kuhl_m_sekurlsa_all() function looks:
NTSTATUS kuhl_m_sekurlsa_all(int argc, wchar_t *argv[]) {
While(__afl_persistent_loop()) {
kuhl_m_sekurlsa_reset(); // sekurlsa::minidump command
pMinidumpName = argv[1]; // sekurlsa::minidump command
kuhl_m_sekurlsa_getLogonData(lsassPackages, ARRAYSIZE(lsassPackages); // sekurlsa::logonpasswords command
}
Return NT_SUCCESS;
}
Hint: Do not use the above code during fuzzing. I added a subtle flaw, which I’m going to explain later. Can you already spot it?
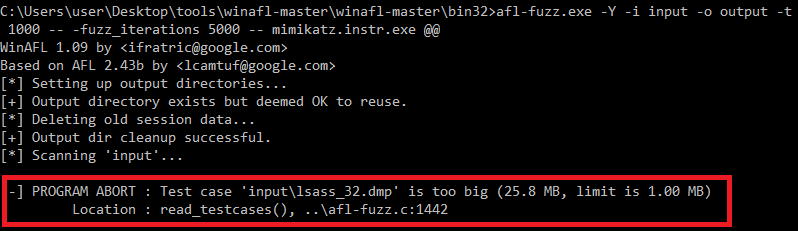
As we can see, we have a file size problem!
Theory: Fuzzing And The Input File Size Problem
We can see that AFL restricts input files to a maximum size of 1 MB. Why? Recall, that AFL is doing deterministic fuzzing before switching to random fuzzing for each queue input. That means that it is doing specific bit and byte flips/additions/removals/… for every (!) byte/bit in the input! This includes several strategies like bitflip 1/1, bitflip 2/1, …, arith 8/8, arith 16/8 and so on. For example, bitflip 1/1 means that AFL flips 1 bit per execution and then walks forward 1 bit to flip the next bit. Whereas 2/1 means that 2 bits are flipped and the step length is 1 bit. Arith 16/8 means that the step is 8 and that AFL tries to add interesting values to a value treated as 16-bit integer. And there are several more such deterministic fuzzing strategies. All these strategies have in common that the number of required application executions depend on the file size!
Let’s just assume that AFL only (!) does the bitflip 1/1 deterministic strategy. This means that we must execute the target application exactly input-filesize (bit) number of times. WinAFL is doing in-memory fuzzing which means that we don’t have to start the application every time, but let’s forget this for now so that our discussion does not get too complicated. Let’s say that our input binary has a size of 10 kB. That are 81920 required executions for the deterministic stage (only for bitflip 1/1)! AFL conducts many more deterministic strategies. For AFL on Linux this is not very huge, it’s not uncommon to get execution speeds of 1000 – 8000 executions / second (because of the fork-server, persistent-mode, …) per core. This fast execution speed together with deterministic fuzzing (and edge coverage) made AFL so successful. So, if we have 16 cores we can easily do this strategy for one input file within a second.
Now let’s assume that our input has a size of 1 MB (AFL limit), which means 8 388 608 required executions for the bitflip 1/1 and that our target application is a little bit slower because it’s bigger and running on Windows (200 exec / sec) and that we just have one core available for fuzzing. Then we need 11,5 hours only to finish the bitflip 1/1 for one input entry! Recall that we must conduct this deterministic stage for every new queue entry (every time we identify new coverage, we must do this again! It’s not uncommon that the queue grows up to several thousand inputs). And if we consider all the other deterministic operations which must be performed, the situation becomes even worse.
And in our case the input (memory dump) has a size of 27 MB! This would be 216 036 224 required executions only for bitflip 1/1. AFL detects this and directly aborts because this would just take too long (and AFL would never find vulnerabilities because it’s stuck inside deterministic fuzzing). Of course, we can tell AFL to skip deterministic fuzzing, but that would not be very good because we still have to find the special byte/bit flip which triggers the vulnerability. And the likelihood for this in such a big input file is not very high….
Here is a cite from Michal Zalewski (author of AFL) from the perf_tips.txt document:
To illustrate, let’s say that you’re randomly flipping bits in a file, one bit at a time. Let’s assume that if you flip bit #47, you will hit a security bug; flipping any other bit just results in an invalid document. Now, if your starting test case is 100 bytes long, you will have a 71% chance of triggering the bug within the first 1,000 execs – not bad! But if the test case is 1 kB long, the probability that we will randomly hit the right pattern in the same timeframe goes down to 11%. And if it has 10 kB of non-essential cruft, the odds plunge to 1%.
The key learning is that input file size is very important during fuzzing! At least as important as plain execution speed of the fuzzer!
There are tools and scripts shipped with AFL (cmin/tmin) to minimize the number of input files and the file size. However, I don’t want to talk about them in this blog post. They shrink files via a fuzzing attempt and since the problem is NP-hard they use heuristics. Tmin is also very slow (execution time depends on the file size…) and often leads to problems with files containing offsets (like our dump file) and checksums. Another idea could be to start WinAFL with an empty input file. However, memory dumps are quite complex and I don’t want to “waste” time while WinAFL identifies the format.
And here is where heatmaps come into play.
Practice: Fuzzing And Heatmaps
My first attempt to minimize the input file was to read the source code of mimikatz and understand how it finds the important memory regions (containing the plaintext passwords and hashes) in the memory dump. I assumed some kind of pattern-search, however, mimikatz parses and uses lots of structures and I quickly discarded the idea of manually creating a smaller input binary by understanding mimikatz. During fuzzing we also don’t want to understand the application to write a specific fuzzer, instead we want that the fuzzer learns everything itself. If we could somehow give the fuzzer the same ability to detect the “important input bytes”…
During reading the code I identified something interesting. Mimikatz loads the memory dump via kernel32!MapViewOfFile(). After that it reads nearly all required information from there (sometimes it also copies it via kull_m_minidump_copy, but let’s not get too complicated for the moment).
If we can log all memory access attempts to this memory region, we can easily reduce the number of required executions drastically! If mimikatz does not touch a specific memory region, why should we even fuzz the bytes there?
The most important message from the above pictures: We do not have to fuzz the bytes from the black area! But we can even do better, we can start fuzzing the white bytes (many read attempts, like offset 0xaa00 which gets read several thousand times), then continue with yellow bytes (e.g.: offset 0x08 is read several hundred times) and then red areas (which are only read 1-5 times). This itself is not a perfect approach (more read attempts also mean that the likelihood that the input becomes invalid gets higher and therefore it’s maybe not the best idea to start with white areas but since we must do the full deterministic step it basically does not matter with which offsets we start; Hint: A better strategy is to also consider the triggering read-instruction address together with the hitcounts).
You are maybe wondering how I extracted the memory-read information. For mimikatz I just used a stupid PoC debugger script, however, I’m currently developing a more sophisticated script with the use of dynamic instrumentation frameworks which can extract such information from any application.
The use of a debugger script is “stupid” because it’s very slow and does not work for every application. However, for mimikatz it worked fine because mimikatz reads most of the time from the region which is mapped via MapViewOfFile().
My WinAppDbg script is very simple, I just use the Api-Hooking mechanism of WinAppDbg to hook the post-routine of MapViewOfFile. The return value contains the memory address where the input memory dump is loaded. I placed a memory breakpoint on it and at every breakpoint hit I just log the relative offset and increment the hit counter. You can also extend this script to become more complex (e.g.: hook kull_m_memory_search() or kull_m_minidump_copy().
Can you spot the problem?
Line 9 allocates space for string->MaximumLength bytes and after that it copies exactly the same number of bytes from the minidump to the heap (line 11). However, the code never checks string->Length and therefore string->Length can be bigger than string->MaximumLength because this value is retrieved from the minidump. If later code uses string->Length a heap overflow can occur. This is for example the case when MSV1.0 (dpapi) credentials are stored in the minidump. Then mimikatz uses the string as input (and output) inside the decryption function in kuhl_m_sekurlsa_nt6_LsaEncryptMemory() and the manipulated length value leads to a heap overflow (however, the MSV1.0 execution path is not trivial/possible to exploit in my opinion, but there are many other paths which use kull_m_process_getUnicodeString()).
Vulnerabilities patch status
At time of publication (2017-09-22) there is no fix available for mimikatz. I informed the author on 2017-08-26 about the problems and received on 2017-08-28 a very friendly answer, that he will fix the flaws if it does not expand the code base too much. He also pointed out that mimikatz was developed as a proof-of-concept and it could be more secure by using a higher level language on which I totally agree on. On 2017-08-28 I sent the SMIME encrypted vulnerability details (together with this blog post). Since I didn’t receive answers on further emails or twitter messages, I informed him on 2017-09-06 about the blog post release on 2017-09-21.
If you are a security consultant and using mimikatz in minidump mode, make sure to only use it inside a special mimikatz-virtual machine which is not connected to the internet/intranet and does not store important information (I hope you are already doing this anyway). To further mitigate the risk (e.g. a VM escape) I recommend to fix the above mentioned vulnerabilities.
Theory: Recommended Fuzzing Workflow
In this last chapter, I want to quickly summarize the fuzzing workflow which I recommend:
- Download as many input files as possible.
- Calculate a minset of input files which still trigger the full code/edge coverage (corpus distillation). Use a Bloom-Filter for fast detection of different coverage. Minimize the file size of all input files in the minset.
- For the generated minset, calculate the code coverage (no Bloom-Filter). Now we can statically add breakpoints (byte 0xCC) at all basic blocks which were not hit yet. This modified application can be started with all files from the input and should not crash. However, we can continue downloading more files from the internet and start the modified binary (or just fuzz it). As soon as the application crashes (and our Just-in-Time configured compiler script kicks in) we know that a new code path was taken. Using this approach, we can achieve native execution speed but extract the information about new coverage! (downside: Checksums from files break; Moreover, a fork-server should also be used.)
- During fuzzing I recommend extraction of edge coverage (which requires instrumentation) and therefore we should fuzz with instrumentation (and sanitizers / heap libraries).
- For every input, we conduct an analysis phase before fuzzing. This analysis phase does the following: First identify the common code which gets executed for most inputs (for this we had to log the code coverage without the bloom-filter). Then get the code coverage for the current input and subtract the common code coverage from it. What we get is the code coverage which makes this fuzzing input “important” (code which only gets executed for this input). Next, we start our heatmap analysis but we just log the read operations conducted by this “important code”! What we get from this are the bytes which make our input “important”. Now we don’t have to fuzz the full input file, nor we have to fuzz the bytes which are read by the application, instead we only have to fuzz the few bytes which make the file “special”! I recommend focusing on these “special” bytes but also fuzz the other bytes afterwards (Fuzzing the special bytes fuzzes the new code, fuzzing all bytes fuzzes the old code with the new state resulting from the new code). Moreover, we can add additional slow checks which must be done only once for a new input (e.g. log all heap allocations and check for dangling-pointers after a free-operation; similar concept to Edge’s MemGC).
- Of course, some additional feedback and symbolic execution.
Want to learn more about fuzzing? Come to one of my fuzzing talks for fuzzing applications or just follow me on Twitter.
This research was done by René Freingruber (@ReneFreingruber) on behalf of SEC Consult Vulnerability Lab.