Vendor Description
“UnZip is an extraction utility for archives compressed in .zip format (also called “zipfiles”). Although highly compatible both with PKWARE’s PKZIP and PKUNZIP utilities for MS-DOS and with Info-ZIP’s own Zip program, our primary objectives have been portability and non-MSDOS functionality. UnZip will list, test, or extract files from a .zip archive, commonly found on MS-DOS systems. The default behavior (with no options) is to extract into the current directory (and subdirectories below it) all files from the specified zipfile.”
Source: http://www.info-zip.org/UnZip.html
InfoZip’s UnZip is used as default utility for uncompressing ZIP archives on nearly all *nix systems. It gets shipped with many commerical products on Windows to provide (un)compressing functionality as well.
Business Recommendation
InfoZip Unzip should be updated to the latest available version.
Vulnerability Overview/ Description
1) Heap-based buffer overflow in password protected ZIP archives (CVE-2018-1000035)
InfoZip’s UnZip suffers from a heap-based buffer overflow when uncompressing password protected ZIP archives. An attacker can exploit this vulnerability to overwrite heap chunks to get arbitrary code execution on the target system.
For newer builds the risk for this vulnerability is partially mitigated because modern compilers automatically replace unsafe functions with length checking variants of the same function (for example sprintf gets replaced by sprintf_chk). This is done by the compiler at locations were the length of the destination buffer can be calculated.
Nevertheless, it must be mentioned that UnZip is used on many systems including older systems or on exotic architectures on which this protection is not in place. Moreover, pre-compiled binaries which can be found on the internet lack the protection because the last major release of InfoZip’s UnZip was in 2009 and compilers didn’t enable this protection per default at that time. The required compiler flags are also not set in the Makefile of UnZip. Compiled applications are therefore only protected if the used compiler has this protection enabled per default which is only the case with modern compilers.
To trigger this vulnerability (and the following) it’s enough to uncompress a manipulated ZIP archive. Any of the following invocations can be used to trigger and abuse the vulnerabilities:
>unzip malicious.zip >unzip -p malicious.zip >unzip -t malicious.zip
2) Heap-based out-of-bounds write (CVE-2018-1000031)
This vulnerability only affects UnZip 6.1c22 (next beta version of UnZip). InfoZip’s UnZip suffers from a heap-based out-of-bounds write if the archive filename does not contain a .zip suffix.
3) Heap/BSS-based buffer overflow (Bypass of CVE-2015-1315) (CVE-2018-1000032)
This vulnerability only affects UnZip 6.1c22 (next beta version of UnZip). InfoZip’s UnZip suffers from a heap/BSS-based buffer-overflow which can be used to write null-bytes out-of-bound when converting attacker-controlled strings to the local charset.
4) Heap out-of-bounds access in ef_scan_for_stream (CVE-2018-1000033)
This vulnerability only affects UnZip 6.1c22 (next beta version of UnZip). InfoZip’s UnZip suffers from a heap out-of-bounds access vulnerability.
5) Multiple vulnerabilities in the LZMA compression algorithm (CVE-2018-1000034)
This vulnerability only affects UnZip 6.1c22 (next beta version of UnZip). InfoZip’s UnZip suffers from multiple vulnerabilities in the LZMA implementation. Various crash dumps have been supplied to the vendor but no further analysis has been performed.
Proof Of Concept
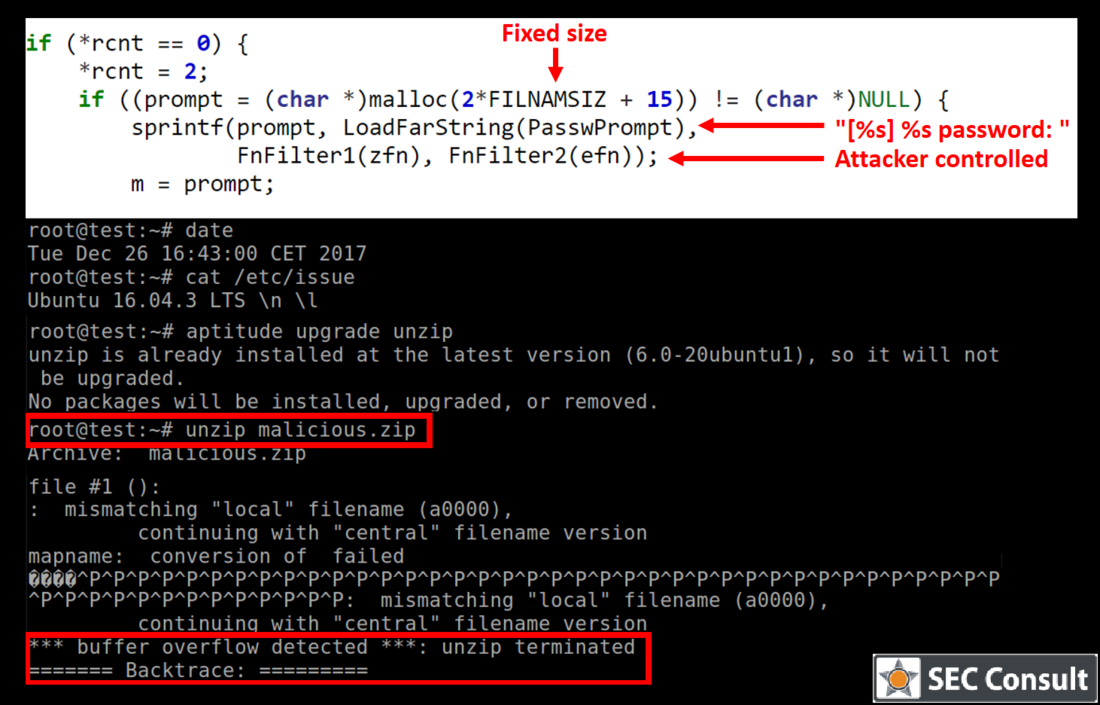
1) Heap-based buffer overflow in password protected ZIP archives (CVE-2018-1000035)
Unzipping a malicious archive results in the following output (on Ubuntu 16.04 with UnZip 6.0 which was installed via aptitude install unzip):
*** buffer overflow detected ***: unzip terminated ======= Backtrace: ========= /lib/x86_64-linux-gnu/libc.so.6(+0x*****)[0x************] /lib/x86_64-linux-gnu/libc.so.6(__fortify_fail+0x**)[0x************] /lib/x86_64-linux-gnu/libc.so.6(+0x*****)[0x************] /lib/x86_64-linux-gnu/libc.so.6(+0x*****)[0x************] /lib/x86_64-linux-gnu/libc.so.6(_IO_default_xsputn+0x**)[0x************] /lib/x86_64-linux-gnu/libc.so.6(_IO_vfprintf+0x**)[0x************] /lib/x86_64-linux-gnu/libc.so.6(__vsprintf_chk+0x**)[0x************] /lib/x86_64-linux-gnu/libc.so.6(__sprintf_chk+0x**)[0x************] unzip[0x40c02b] unzip[0x4049ac] unzip[0x40762c] unzip[0x409b60] unzip[0x411175] unzip[0x411bdf] unzip[0x404191]
Function names can be mapped to the backtrace by compiling the application with debug symbols:
(gdb) backtrace #0 0x000000000040c706 in UzpPassword () #1 0x00000000004043ce in decrypt () #2 0x000000000040731c in extract_or_test_entrylist () #3 0x00000000004094af in extract_or_test_files () #4 0x00000000004149a5 in do_seekable () #5 0x000000000041540f in process_zipfiles () #6 0x0000000000403921 in unzip ()
The vulnerability resides inside the UzpPassword function in the following code snippet (file ./fileio.c):
[1591] if ((prompt = (char *)malloc(2*FILNAMSIZ + 15)) != (char *)NULL) { [1592] sprintf(prompt, LoadFarString(PasswPrompt), [1593] FnFilter1(zfn), FnFilter2(efn)); ... [1595] }
The allocation at line 1591 allocates a fixed size buffer and then writes into it at line 1592. It writes the following format string (PasswPrompt) into the buffer: “[%s] %s password: ”
This string has a length of 15 including the null-termination which explains the +15 in the allocation. The developer allocated 2*FILENAMESIZ which corresponds to 2 * PATH_MAX for the two format strings (zfn and efn). zfn is the archive filename and can therefore not exceed PATH_MAX. efn is the current processed filename inside the ZIP archive which should typically be smaller than PATH_MAX for normal files. However, since an attacker can manipulate the archive file the name can arbitrarily be chosen which leads to a heap-based buffer overflow.